As a follow-up of my previous study of Australian politicians on Twitter I’ve decided to build a more sophisticated, autonomous solution.
The idea at glance:
- Collect regularly tweets from Members of Australian Parliament
- Store them in the database
- Visualize findings (in up-to-date state) in web dashboard
A goal here is to build a solution that once created will work fully autonomously, without need for me to run any single update script manually and present the insights to people who don’t have R for various reasons. It is quite common situation in business when analysts need to build a dashboard that then used by non-technical users.
Architecture
Data collection
For data collection I’ve decided to use R as a language. It was tempting to play with something like Lambda functions that AWS offers, but there is no R support yet and my Python skills are too basic and I would spend too much time to build something working. The challenge with R is to make it running: (a) on server rather than desktop and (b) have scheduled tasks for regular data collection.
Running R on server isn’t something very novel, there are number of solutions available. I’ve decided to go with the bundle server solution created Louis Aslett. It includes R, open-source versions of RStudio and Shiny (which I’ll use for visualization part).
Running R script on schedule is possible thanks to CronR package (also available through CRAN).
Data storage
For data storage I selected popular relational database MySQL (at AWS RDS). It isn’t very sexy, but the data I am collecting isn’t huge at the moment (a bit over 20,000 records) and nearby future, so more complex solution will be probably an overkill. I also use some DB functionality to process data before it goes back to application: avoid data duplication and merge 2 data tables.
Visualization
For visualization I employ Shiny Open Source server. It is part of the package referred above and works just fine for my purpose.
A high level diagram of the solution is presented below.
Let’s now talk about some details.
RStudio and Shiny server setup
As was mentioned I am using an image (AMI) prepared by Louis Aslett. The image is build to easy and quickly deploy the whole server to Amazon Web Services infrastructure. It takes literally 15-20 minutes to do initial deployment and pretty straight forward in general, you need just follow the instructions.
What may take a bit of time is to set it work through secure HTTPS connection.
I’ve managed to achieve it by using self-signed certificate and free account on Cloudflare
Prerequisite: you need to have a domain managed through Cloudflare.
Instructions how to do it.
1. Configure domain or sub-domain pointing to your new EC2 instance. I’ve used CNAME record pointing to Public DNS (IPv4) of my instance. Make sure that you set Full SSL mode in Crypto section of Cloudflare
2. Generate self-signed SSL certificate as per Step One of this instruction provided by Digital Ocean. Note that you don’t need to install Nginx, it is already installed.
3. Find Nginx configuration file, specifically with this AMI it is /etc/nginx/sites-available/RStudioAMI.conf
Add there the next lines under Server section:
# Add SSL support
listen 443 ssl default_server;
listen [::]:443 ssl default_server;
ssl_certificate /etc/nginx/ssl/nginx.crt;
ssl_certificate_key /etc/nginx/ssl/nginx.key;
server_name yourdomain.com
Don’t forget to replace yourdomain.com with your actual domain
4. Restart Nginx with sudo service nginx restart
If you did all correctly you now should have your Rstudio available under your domain and Shiny running under yourdomain.com/shiny/rstudio
Database configuration
I will not write a tutorial of setting up RDS instance with MySQL, there are tons of them available and in fact you don’t have to use AWS. What is important that at the end of the process you should be able to connect to your database from remote server or desktop through 3306 port.
For security you may keep it open only for whitelisted IPs (like your home computer and R server you created).
There are several things that I deliberately decided to do on database level.
Initial data collection
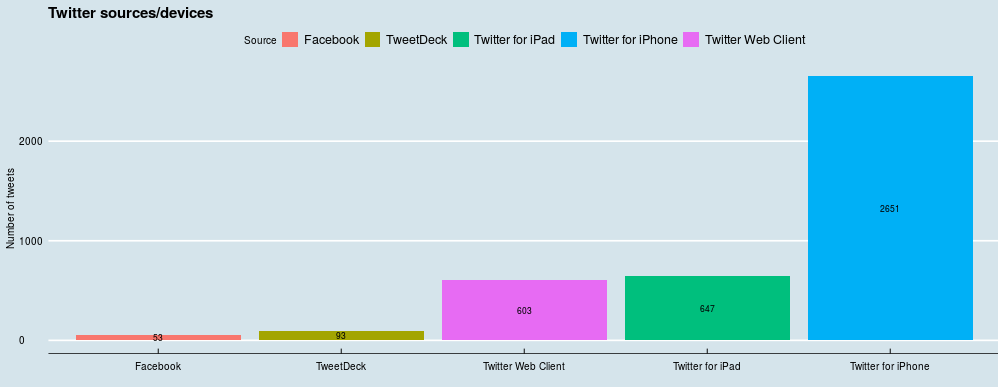
I set some groundwork of collecting tweets from Australian MPs before, so already have list of Members of Parliaments Twitter accounts grouped by parties and a script that collects the tweets.
You may find my script that does initial data collection on Github. This script uses rtweet package to get data from Twitter and RMySQL package to work with MySQL database.
Key commands to work with databases from R:
Setup db connection
con <- dbConnect(RMySQL::MySQL(), dbname= db_name, username=user, password=pw, host=host, port=3306)
Save data in DB from data frame:
dbWriteTable(con, "tweets2", t, row.names=FALSE, append=TRUE)
Close DB connection:
dbDisconnect(con)
What is also important to mention is that data frame has to be flatten before stored to the database, hence flatten function from rtweet package is applied. At the end of this process initial data about tweets and users will be stored in 2 database tables.
Keep the data of tweets and users unique
Each tweet and Twitter user has unique id. For data integrity we don’t want to collect duplicate records of users and tweets. It is possible to handle that on application level (in R code), but because the plan is doing regular updates to make R code simpler and quicker (do not upload all database for integrity check) I decided to set the database such a way that that the records be kept unique on database level.
So I set the fields user_id and status_id in corresponding tables as unique. In SQL it looks like:
`user_id` varchar(50) NOT NULL,
PRIMARY KEY (`user_id`),
UNIQUE KEY `user_id_UNIQUE` (`user_id`)
Don’t copy-paste this code, because it misses all the other fields in the table. If you don’t know SQL you can easily set that configuration through tool like MySQL Workbench. Similar approach used with status_id in table with tweets.
Joining users and tweets.
To make more sense of data, like link tweets with political party we need to join the data of tweets and users. Previously I did that in R code, which is comparatively easy with dplyr. However why not make the DB do this job? Hence I have created a view in MySQL that joins tweets and users table based the next SQL code:
SELECT
twitterr.tweets2.*,
twitterr.users2.party AS 'party'
FROM
(twitterr.tweets2
LEFT JOIN twitterr.users2 ON ((twitterr.tweets2.user_id = twitterr.users2.user_id)))
As a result, MySQL on fly creates a view that later can be requested the save way with a table, which is pretty handy – you can load a joined data straight to your data frame for further analysis and visualization.
If you need part of data you can construct a custom SQL query and get for example only last week data set or only a data set covering one party.
That is it for now, stay tuned.
If you can’t wait – all R code is available at my Github repository.
The Shiny application can be checked here: https://rserv.levashov.biz/shiny/rstudio/